
ipwn
C) 포인터, 문자와 문자열 처리 함수, 구조체 본문
1. 포인터란?
포인터는 메모리의 주소 값을 저장하기 위한 변수를 의미합니다. 그러므로 (주소값 != 포인터)
포인터의 크기는 컴퓨터의 주소 체계에 따라 크기가 결정되는데요 , 32비트 기반 시스템에서는 4 바이트 크기 입니다.
(64바이트 기반 시스템에서는 8바이트)
포인터 선언시에 사용되는 연산자는 * 인데,
자료형을 A로 하고 포인터를 선언한다고 하면 A *변수이름이 되는데 예를 들어
int *a; |
라고 한다면 int형 a라는 이름의 포인터가 되는 것입니다.
즉 자료형A *b는 A타입의 b라는 포인터 변수가 생성되는 것입니다.
주소 관련 연산자(포인터)로는 &연산자와 *연산자가 있는데
& 연산자는 변수의 주소 값을 반환하는 연산자이고
* 연산자는 포인터가 가르키는 메모리를 참조하는 , 즉 직접적으로 그 메모리 공간에 다가가는 연산자입니다.
int a=3000;//a의 값은 3000 int *pA = &a;//포인터 변수 선언 pA == a의 주소값을 의미 *pA = 200;//직접적으로 접근해 pA가 가르키는 곳의 값을 200으로 바꿔버림 == a를 200으로 바꿈 |
즉 이런식으로 직접적으로 접근해서 메모리를 건들 수 있는 것입니다.
2.포인터와 배열
포인터와 배열은 엄청 가까운 상관 관계를 갖고 있습니다.
배열의 이름은 그 배열의 첫 번째 요소의 주소 값을 나타내는데요,
그 말은 즉
int a[5]; printf("%#x\n",&a[0]); printf("%#x",a); |
위 코드에서의 출력되는 값은 똑같다는걸 알 수 있습니다.
포인터와 배열은 이와같이 주소를 가르킨다는 점에서 비슷하지만
다른점이 있다면 포인터는 변수지만 배열은 상수라는 점입니다.
즉
int a = 200; int *pA = &a; |
위 코드는 가능하지만,
int a = 200; int b[5] = {0, 1, 2, 3, 4}; b = &a; |
위 코드는 b라는 배열이 변수였다면 가능하겠지만, 상수이기 때문에 불가능합니다.
포인터에 타입이 존재하듯이 배열 이름에도 타입이 존재하는데요,
배열이름이 가르키는 배열 요소에 의해서 결정 됩니다.
배열 이름을 포인터처럼 , 포인터를 배열 이름처럼 사용하는 것 도 가능합니다!
int arr[3]={0, 1, 2}; int *ptr; ptr = arr; printf("%d, %d, %d \n", ptr[0], ptr[1], ptr[2]); |
위 코드를 보면 알겠지만 포인터 변수 ptr에 arr이라는 배열을 대입해서
ptr을 배열처럼 사용하는 것이 가능합니다.
포인터는 또한 연산도 가능한데요, 포인터가 가르키는 대상의 자료형에 따라서 증감하는 값이 달리집니다.
즉 int 형은 4바이트이므로 1증가할 때 마다 4씩 증가하고, double형은 8바이트이므로 1증가 할 때 마다 8씩 증가하는 것과 같은 형식입니다.
단 *,/와 같은 연산자는 불가능하다고 합니다.
포인터 연산을 통해서 배열에 접근도 할 수 있는데요,
int arr[5] = { 0,1,2,3,4 }; int *pArr = arr; printf("%d \n", *pArr);//배열의 첫 째 순서 printf("%d \n", *(++pArr));//배열의 둘 째 순서 printf("%d \n", *(++pArr));//배열의 셋 째 순서 printf("%d \n", *(pArr + 1));//배열의 넷 째 순서 printf("%d \n", *(pArr + 2));//배열의 다섯 째 순서 |
이런 식으로 접근이 가능합니다.
여기서 우리가 얻을 수 있는 결론은
int arr[2] = {0,1}; int *pArr = arr; |
라는 조건이 있는 경우 arr[i] == *(arr + i)라는 점입니다.
또 pArr == arr이므로
pArr[i] == *(pArr + i) 라는 점도 알 수 있습니다.
또한 문자열 상수를 카르키는 포인터도 있습니다.
우리는 문자열을 선언할 때 아래와 같은 방식으로 선언을 합니다.
char str[5] = "abcd";// a,b,c,d,NULL 와 같음 |
이와 같은 방식은 배열 기반의 문자열 변수인데요,
각 배열 요소들에 a,b,c,d,NULL이 각각 대입이 된 것인 걸 알 수 있습니다.
포인터를 이용하면 포인터 기반의 문자열 상수도 생성 할 수 있습니다.
char *str = "abcd";// a b c d NULL 와 같음 but 배열과 달리 상수 |
포인터를 이용한 문자열 상수는 위와같이 선언이 되는데요 배열 기반의 문자열 변수는
char str[5] = "abcd";// a,b,c,d,NULL 와 같음 str[0] = 'X';//가능 |
이와 같은 방식으로 변경을 해 줄 수 있지만
char *str = "abcd"; // a b c d NULL 와 같음 but 배열과 달리 상수 str[0] = 'X'; // ERROR!!!! |
위와 같이 변경을 하려고 하면 포인터 기반의 문자열 상수이기 때문에 에러가 나 버립니다.
또 포인터 배열이라는 것도 존재하는데요, 이 것은 배열의 요소들로 포인터들을 지니는 배열을 의미합니다.
선언 방식은 일반 배열 선언과 비슷합니다.
int *a[10]; double *b[10]; char *c[10]; |
선언 방식은 이와 같은 방식으로 이루어 집니다.
1차원 배열의 경우 배열이름이 가리키는 대상을 통해 타입이 결정되는데 이 것은 포인터 배열도 마찬가지입니다.
예를 들어서 아래와 같은 방식으로 사용을 한다면,
int *a[3]; int b = 10, c = 20, d = 30; a[0] = &b; a[1] = &c; a[2] = &d; |
각 배열 요소에 순서대로 b c d의 주솟값을 넣어주고 *연산자를 이용하여 각 메모리들을 불러올 수 있습니다.
또한 아래와 같은 방식으로
char *str[3] = {//각 요소들에 문자열 상수 대입 "우와앙", "짱이당", "헤헤헤" }; |
각 배열 요소들에 문자열 상수를 대입하는 것 도 가능합니다.
3.포인터와 함수
포인터를 잘 몰랐던 때에의 함수는 보통 값을 복사해서 함수몸체에서 실행을 마친 뒤 그 값을 반환하는 형식(call by value)이 다 였습니다.
예를 들어 본다면
#include<stdio.h> int plus(int n1, int n2) {//a와 b값을 main함수에서 복사해 와서 n1 , n2를 더한 값을 반환 return n1 + n2; } int main() { int a, b; scanf("%d %d", &a, &b); printf("%d", plus(a, b));//plus함수에서 반환 된 값 출력 return 0; } |
이와 같이 아주 간단하게
1.메인함수에서 메모리 값들을 복사
2.함수 내에서의 행위 후 반환 같이 간단한 절차만 거치는게 다 였습니다.
하지만 포인터를 이용한다면 각 메모리의 주솟값을 받아와서 함수들을 이용해 그 안의 메모리들을 마음대로 사용할 수 있습니다.(call by reference)
이 것은 블로그 내에 있는 swap함수를 구현 한 것을 참고하면 될 것 같습니다.
여기서의 swap함수는 변수 두개의 주소를 받아 그 주소안의 메모리 값을 바꿔주는 함수를 의미합니다.
또한 배열은 배열이름 그 자체가 주솟값을 가르키기 때문에 배열을
이용한 함수를 사용 할 때는 반드시 포인터를 사용해야 합니다.
또 const라는 키워드를 이용해 포인터 자체를 상수화 시켜버리거나, 포인터 안의 변수를 상수화 시키는 것 도 가능합니다.
아래와 같이 const문을 써 준다면 주석처리한 것 들과 같이 처리 되지만
int a = 10; const int *p = &a;//포인터가 가르키는 변수를 상수화 *p = 30;//에러가 나버림 (*p안에 있는 상수를 강제로 변경하려 함) a = 30;//가능함 (a는 변수임) |
아래와 같이 const문을 써 준다면 주석처리한 그대로 처리가 됩니다.
int a = 10; int b = 20; int *const p = &a;//포인터 자체를 상수화 p = &b;//불가능 (p라는 포인터는 상수가 됐기 때문에) *p = 30; //가능함 (포인터가 가르키는 변수는 여전히 변수) |
const를 사용하는 이유는 프로그램을 더 안정적으로 구성하기 위함입니다.
4.포인터의 포인터
포인터의 포인터 즉 더블 포인터는 싱글 포인터의 주소 값을 저장하는 용도의 포인터입니다.
#include <stdio.h> void pswap(int **p1, int **p2); int main(void) { int A=10, B=20; int *pA, *pB; pA = &A, pB = &B; pswap(&pA, &pB); printf("pA가 가리키는 변수 : %d \n", *pA); printf("pB가 가리키는 변수 : %d \n", *pB); return 0; } void pswap(int **p1, int **p2)//포인터의 주소값을 가져오므로 더블 포인터 사용 { int *temp;//주소값을 저장할 포인터 변수 선언 temp = *p1;//temp라는 포인터 변수에 pA가 가르키는 곳 즉 A의 주소를 대입 *p1 = *p2;//pA가 가르키는 곳 즉 A의 주소에 pB가 가르키는 곳 즉 B의 주소를 대입 *p2 = temp;//pB가 가르키는 곳 즉 B의 주소에 temp == pA가 가르키는 곳 즉 A의 주소를 대입 } |
이런식으로 더블 포인터를 이용한 스왑함수도 구현이 가능합니다!!
5.다차원 배열과 포인터
다차원 배열이란 2차원 배열 이상의 배열을 의미하는데요,
근데 다차원 배열도 사실은 실제 차원이 있는것이 아니라 1차원 배열과 같이 메모리가 구성이 되지만,
차원이 있다고 생각하고 구조적으로 이해하는 것이 좋은 습관이기도 하며 정신건강에도 좋습니다.
다만 3차원 배열 까지는 구조적으로 이해가 가능하지만 4차원 배열 이상으로 넘어가면 구조적으로 이해가 불가능합니다.
어처피 크게 쓰이지 않으니 개념만 이해해도 충분합니다.
1차원 배열의 포인터 타입 결정은 포인터가 가르키는 요소의 자료형, 포인터 연산시 증가하는 바이트 크기였습니다.
그리고 1차원 배열의 이름이 가르키는 요소의 자료형이 일치하면, 포인터 연산시 증가하는 값의 크기도 일치했는데요
따라서 1차원 배열의 경우 가르키는 요소만 참조를 했습니다.
하지만 다차원 배열에서는 약간 다릅니다.
포인터 타입을 결정해주는 포인트는 포인터가 가르키는 요소의 자료형, 연산시 증가하는 바이트 크기라는 것에 다른점이 없지만,
포인터가 가르키는 요소의 자료형이 같다고 해도 포인터 연산시 증가하는 값의 크기가 불일치 합니다 따라서 포인터 연산 결과도 생각해 봐야 합니다.
밑과 같은 코드가 있다고 하면
int a[3][2] = { 0,1,2,3,4,5 }; //a[0] == &a[0][0] //a[1] == &a[1][0] //a[2] == &a[2][0] |
위에 주석처리한 설명대로 표현이 됩니다.
또 추가로 a == &a[0][0], a + 1 == &a[1][0], a + 2 == &a[2][0]도 성립됩니다.
즉 a == a[0], a + 1 == a[1], a + 2 == a[2] 라는 것을 알 수 있습니다.
2차원 배열 이상의 포인터 타입 구성은 가리키는 대상의 자료형, 포인터 연산시 증가하는 바이트 크기로 구성됩니다.
int (*pArr)[4]; |
위와 같은 코드도 짤 수 있는데요, 이와 같은 코드는 int형 변수 4칸식 건너뛰는 배열 포인터를 의미합니다.
즉 가로로 4칸 세로로 ?칸인 배열을 의미하는데
int (*pArr)[4]; int arr[2][4]; pArr = arr; |
위와 같이 코드를 짜게 된다면 (*pArr)[4] == arr[2][4] 가 됩니다.
즉 가로로 4칸 세로로 2칸인 배열입니다.
또한 pArr[0][0] == arr[0][0], pArr[0][1] == arr[0][1] .... pArr[1][3] == arr[1][3] 이 되는 것입니다.
위와 같이 이차원 배열처럼 사용 가능한 반면
#include<stdio.h> int main() { int a[2][4] = { 0,1,2,3,4,5,6,7 }; int(*pArr)[4]; pArr = a; printf("%d\n", (*pArr)[7]); } |
이런 식으로 1차원 배열처럼 사용도 가능합니다.
int *pArr[n] 은 포인터 배열이고
int (*pArr)[n] 은 배열 포인터이므로 엄연히 다른 존재입니다.
6.문자와 문자열 처리 함수
스트림 : 데이터를 송/수신 하기 위한 다리
입/출력에는 파일, 콘솔, 소켓 등의 입/출력이 있습니다.
표준 입/출력 스트림에는 stdin, stdout, stderr등이 있는데
이 것들은 프로그램 실행시 자동으로 생성 및 소멸됩니다.
각자 모니터,키보드를 대상으로 삼습니다.
stdin == 표준 입력 스트림 (입력 장치 == 키보드)
stdout == 표준 출력 스트림 (출력 장치 == 모니터)
stderr == 표준 에러 스트림 (출력장치 == 모니터)
문자 출력 함수로는
#include <stdio.h> int putchar(int c); int fputc(int c, FILE* stream) |
위의 코드가 있습니다 에러가 발생하는 경우 EOF를 리턴합니다.
문자 입력 함수로는
#include <stdio.h> int getchar(); int fgetc(FILE* stream); |
위의 코드가 있는데 에러가 발생하거나 파일의 끝에 도달하는 경우 EOF를 리턴합니다.
여기서 EOF란 End-Of-File의 약자로 파일의 끝을 표현하기 위한 상수를 의미합니다.(-1의 값을 지닙니다)
콘솔의 경우 ctrl-Z가 파일의 EOF를 의미한다고 합니다.
문자 단위의 입/출력 함수가 필요한 이유는 용도에 맞는 적절한 함수를 제공하므로써 성능 향상을 도모하기 위함이라고 합니다.
문자열 출력 함수로는
#include <stdio.h> int puts(const char* s); int fputs(const char* s, FILE* stream) //stdin |
위와 같은 코드가 있는데 문자 출력 함수와 같이 에러 발생시 EOF를 반환합니다.
문자열 입력 함수로는
#include <stdio.h> char* gets(char* s); char* fgets(char* s, int n, FILE* stream); //stdout |
위와 같은 코드가 있는데 에러가 발생하거나 파일의 끝에 도달시 NULL 포인터를 반환합니다.
버퍼 : 한 곳에서 다른 곳으로 데이터를 이동할 때 임시적으로 그 데이터를 저장하기 위해 사용되는 물리적인 메모리 저장소의 영역.
입출력 사이의 버퍼에는 여분의 임시 메모리적 특징을 지닌다고 합니다.
버퍼를 비워주는 작업을 하는 fflush 함수도 있는데요
#include <stdio.h> int fflush(FILE * stream); |
이와 같은 방식으로 사용이 되는데 성공시 0, 실패시 EOF를 반환합니다.
문자열을 조작하는 함수들도 있는데요 구조체 전 까지 전부 문자열을 조작해주는 함수들입니다.
아래의 코드는 문자열의 길이를 반환하는 strlen 함수입니다.
#include <stdio.h> size_t strlen(const char* s) |
성공시 0 실패시 EOF를 반환합니다.
또 아래의 코드는 문자열을 복사해주는 함수입니다.
#include <string.h> char* strcpy(char* dest, const char* src); char* strncpy(char* dest, const char* src, size_t n); |
리턴 시에는 복사된 문자열의 포인터를 리턴합니다.
#include <string.h> char* strcat(char* dest, const char* src); char* strncat(char* dest, const char* src, size_t n); |
또 위의 코드는 문자열을 추가해주는 함수들인데요, 리턴 시에는 추가된 문자열의 포인터를 리턴합니다.
아래의 이 코드는 문자열을 비교 해 주는 코드입니다.
#include <string.h> int strcmp(const char* s1, const char* s2); int strncmp(const char* s1, const char* s2, size_t n); |
위 코드에서의 리턴값이 0보다 클 경우는 s1이 s2보다 큰 경우이며 둘이 완전히 같은 경우는 0으로 리턴,
s2가 s1보다 크다면 리턴값이 0보다 작아집니다.
문자열을 숫자로 변환하는 함수들도 있는데요
아래와 같이 사용됩니다.
#include <stdlib.h> int atoi(char *ptr); // 문자열을 int형 데이터로 변환 long atol(char *ptr); // 문자열을 long형 데이터로 변환 double atof(char *str); // 문자열을 double형 데이터로 변환 |
결과는 주석처리 된 대로 이루어 집니다.
또한 대/소문자 변환을 처리하는 함수도 있습니다.
#include <ctypes.h> int toupper(int c); // 소문자를 대문자로 int tolower(int c); // 대문자를 소문자로 |
위와 같이 사용이 되는데 , 역시나 결과는 주석처리한 대로 이뤄 집니다.
7.구조체
구조체의 정의는 하나 이상의 기본 자료형을 기반으로 해 사용자 정의 자료형을 만들 수 있는 문법 요소를 뜻합니다.
선언 방법은
struct jaryo{ int a; int b; }; |
와 같이 이루어 집니다.
이렇게 선언하면 jaryo라는 이름의 구조체를 선언한 것이며 그 안의 int자료형 멤버 a,b를 갖고 있는 것을 의미합니다.
이렇게 만들어진 구조체를 선언하는 방법은 두 가지가 있는데요, 먼저 첫 번째로는 아래와 같이 선언합니다.
struct jaryo{ int a; int b; }p1, p2, p3; |
이렇게 선언하게 되면 p1에 int자료형 a와 b가 생성되고 p2에도 또 p3에도 마찬가지로 p1과 똑같이 생성이 됩니다.
struct jaryo{ int a; int b; }; int main(){ struct jaryo p1, p2, p3; } |
두 번째로는 위와 같은 방식인데 첫 번째 방법과 결과는 같습니다.
구조체에 접근하는 방법은 아래와 같습니다.
struct jaryo{ int a; int b; }; int main(){ struct jaryo p1; p1.a=10; p1.b=20; } |
의미는 p1의 멤버 a에 10을 대입하고 p1의 멤버 b에 20을 대입한 것입니다.
구조체 변수의 초기화 방법은 배열의 초기화 방법과 동일합니다.
struct person { char name[20]; char phone[20]; int age; }; int main () { struct person p = {"안건희", "010-1234-5678", 17}; } |
위와 같이 이뤄집니다.
즉 name문자열에 "안건희"가 들어가고 phone 문자열에는 "010-1234-5678" 이 들어가게 되며 age에는 17이 대입됩니다.
struct bae{ int a; int b; int c; }; int main () { struct bae arr[10]; } |
또한 위와같이 구조체를 배열처럼 선언 할 수 도 있는데 이 코드는 즉
a, b, c라는 멤버를 10개씩 선언 한 것과 같습니다.
배열 요소에 접근하는 방법은 일반 배열과 같게 접근을 합니다.
struct bae{ int a; int b; int c; }; int main () { struct bae arr[10]; arr[1].a = 30, arr[1].b = 20, arr[1].c = 10; } |
위와 같은 방식으로 구조체 배열 요소에 접근합니다.
또 아래와 같은 방식도 가능합니다.
struct bae { int a; int b; int c; }; int main() { struct bae arr[10]; arr[1] = { 0 ,1 ,2 }; } |
결과는 아래와 같이 둘 다 같습니다.
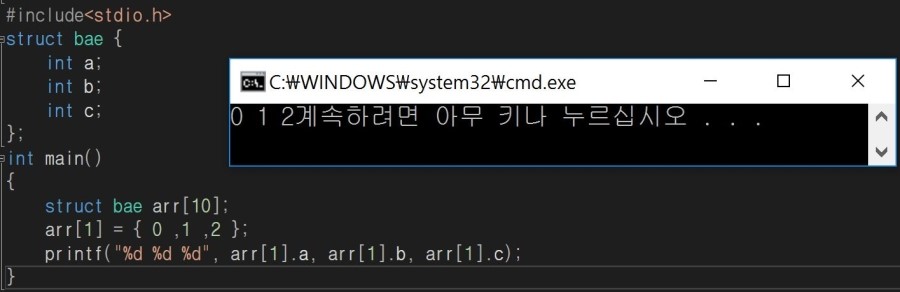
구조체에 포인터가 사용되는 경우는 두 가지가 있는데요,
첫 째로는 구조체 포인터를 선언하여 구조체 변수를 가르키는 경우,
둘 째로는 구조체 멤버로 포인터 변수가 선언된 경우 두 가지 입니다.
또 구조체는 배열과 비슷하게 구조체의 주소는 구조체의 첫 번째 멤버 변수의 주소 값과 같습니다.
함수의 인자로 구조체 변수가 전달되는 방식은 일반 자료형 변수의 인자 전달 방식과 동일합니다.
구조체 변수의 연산에서 허용되는 대표 연산자는 대입연산자( = )이며, 이외의 사칙 연산은 불가능합니다.
또한 구조체 변수의 리턴 방식도 기존 자료형의 리턴 방식과 동일하다고 합니다.
이러한 구조체의 유용한 점은 잘 구현되어 있는 프로그램은 처리 되어야 할 데이터의 부류가 적절히 나누어집니다.
또, 부류를 적절히 나눠주면 데이터를 처리하는 과정이 수월해집니다.
구조체의 멤버로 구조체가 오는 경우도 존재합니다.
이러한 중첩된 구조체를 초기화 하는 방법에는 여러가지가 있습니다. 첫 째로는
struct point { int a; int b; }; struct circle { point a; double c; }; int main() { circle c = { 1, 2, 2.34 }; } |
위와 같은 방식인데요 point 구조체 까지 올라가서 point 구조체 멤버 a, b에 1, 2를 대입해주고 circle멤버 c에는 2.34를 대입합니다.
또 1, 2를 중괄호로 감싸주어도 결과는 아래와 같이 같습니다. ( { {1, 2}, 2.34} 와 같이 해 주어도 됨)
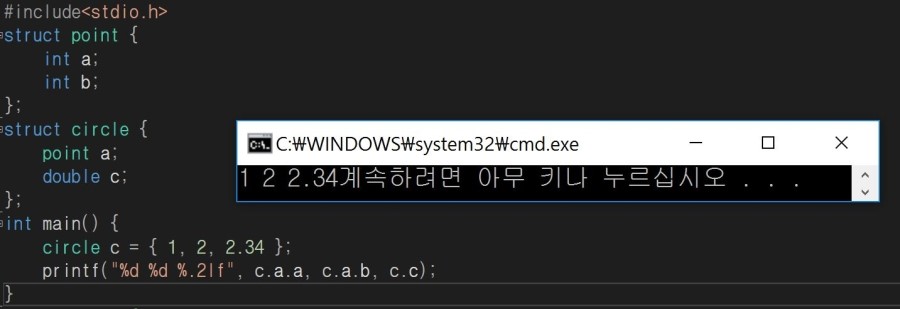
또 아래와 같이 코드를 짜게 된다면,
struct point { int a; int b; }; struct circle { point a; double c; }; int main() { struct circle c = { 1,2 }; } |
circle 멤버 c에는 디폴트값 즉 0이 들어가게 되고, 또 아래와 같이 코드를 짠다면,
struct point { int a; int b; }; struct circle { point a; double c; }; int main() { struct circle c = { {1} ,2.34 }; } |
circle멤버 c에는 2.34가 대입되며 point 멤버 a에는 1 대입 b에는 디폴트값 즉 0이 대입됩니다.
typedef 키워드는
typedef int INT; |
위와 같은 방식으로 사용되는데요, 이 말은 즉 자료형 int의 이름을 INT라는 또 다른 이름을 지어준다는 의미입니다.
공용체는 하나의 메모리 공간을 둘 이상의 변수가 공유하는 형태입니다.
struct s { int a; char c; double b; }; |
위와 같이 구조체를 만들면 b는 b대로 double형이니 8바이트, c는 char형이니 1바이트, a는 int형이니 4바이트 총 13바이트를 사용하게 되는데요,
공용체는 이와 달리
union u_data { int a; double b; char c; }; |
이런 코드가 있다고 가정하면 8바이트 안에 모든 변수가 들어갑니다.
즉 8바이트에서 b는 8바이트를 모두사용하고 c는 1바이트만 a는 4바이트만 사용하는 것 입니다.
열거형은
enum color {RED = 1, GREEN = 3, BLUE = 5} |
위와 같은 코드로 이루어 지는데요
color이라는 자료형과 함께 상수 RED(1),GREEN(3),BLUE(5)를 각각 선언한 것입니다.
이러한 열거형을 사용하는 이유는 특정 정수 값에 의미를 부여할 수 있으며 프로그램의 가독성을 높이는 데 한 몫을 하기 때문입니다.
'Programming' 카테고리의 다른 글
| [memory] 메모리 구조 (0) | 2018.01.08 |
|---|---|
| C) 코드업 함수문제 풀이 (0) | 2017.12.18 |
| C) swap 함수 구현 (0) | 2017.12.18 |
| C) 포인터 (0) | 2017.12.18 |
| C) strlen, strcmp, strcpy 함수 조사 및 구현 (0) | 2017.12.18 |
